Teams of GPT-4 instances can work together to autonomously identify and exploit zero-daysecurityvulnerabilities, without any description of the nature of the flaw. This new development, with a planning agent commanding a squad of specialist LLMs, works faster and smarter than human experts or dedicated software.
Researchers at the University of Illinois Urbana-Champaign (UIUC) have been studying AI’s ability to hack security vulnerabilitiesfor months now, first publishing on ChatGPT’s unparalleled ability to breach security flaws when provided with descriptions of the nature of the vulnerability. The new ground broken since has been innovating on the university’s HPTSA (Hierarchical Planning and Task-Specific Agents) system, which has allowed the GPT-4 model to work in teams to become more than twice as effective.

As outlined in theJune studyand researcher Daniel Kang’s ownblog post, HPTSA uses a collection of LLMs to solve problems with higher success rates. Kang describes the need for this system: “Although single AI agents are incredibly powerful, they are limited by existing LLM capabilities. For example, if an AI agent goes down one path (e.g., attempting to exploit an XSS), it is difficult for the agent to backtrack and attempt to exploit another vulnerability.” Kang continues, “Furthermore, LLMs perform best when focusing on a single task.”
The planner agent surveys the website or application to determine which exploits to try, assigning these to a manager that delegates to task-specific agent LLMs. This system, while complex, is a major improvement from the team’s previous research and even open-source vulnerability scanning software. In a trial of 15 security vulnerabilities, the HPTSA method successfully exploited 8 of the 15 vulnerabilities, beating a single GPT-4 agent which could only get 3 out of 15, and destroying the ZAP and MetaSploit software, which could not exploit a single vulnerability.
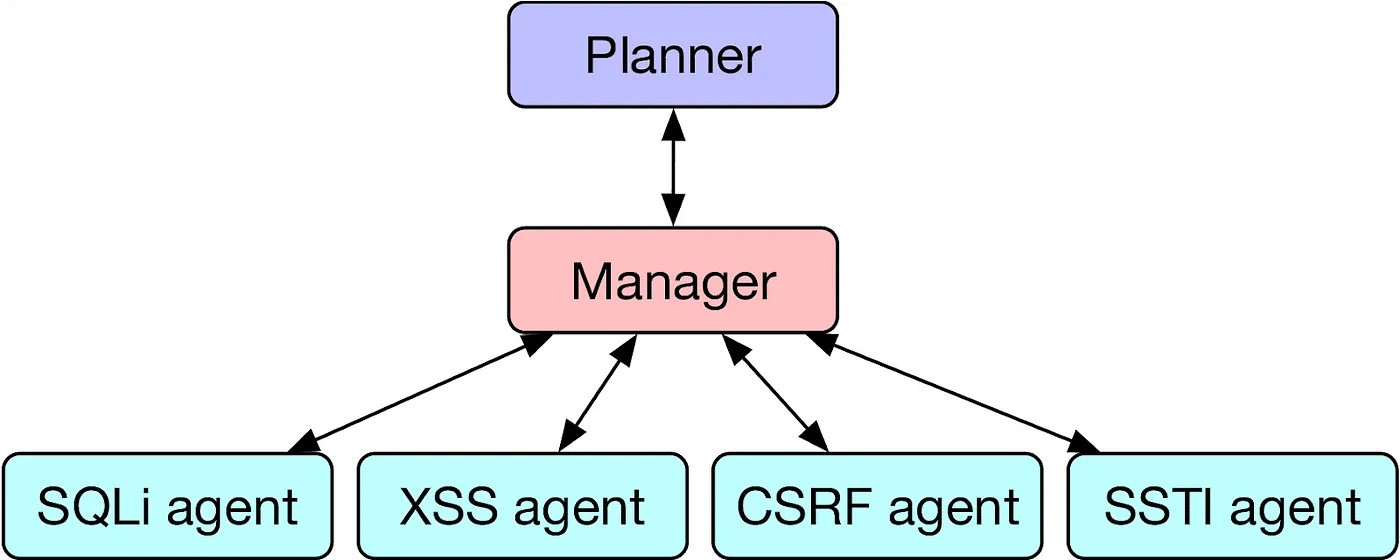
HPTSA was only beaten by a GPT-4 agent that was given a description of the vulnerability in its prompt – which had 11 out of 15 successes. This agent was the pinnacle of UIUC’s original April study, which was found to be superior to human hackers in speed and effectiveness.
OpenAI specifically requested the paper’s authors not make the prompts they used for these or the first experiments public — the authors agreed and said they will only make the prompts available “upon request.” GPT-4 continues to be the research team’s LLM of choice; previous testing using competitor LLMs found them to be severely lacking, and the updatedGPT-4ois not substantially better than GPT-4 in quality.

The UIUC team’s research continues outlining the disturbing truth that large language models have capabilities beyond what is evident on the surface. OpenAI evaluates its software’s safety based on what it can find from the surface-level chatbot, but with careful prompting, ChatGPT can be used to crack cybersecurity or even teach youhow to cook meth.
Get Tom’s Hardware’s best news and in-depth reviews, straight to your inbox.
Sunny Grimm is a contributing writer for Tom’s Hardware. He has been building and breaking computers since 2017, serving as the resident youngster at Tom’s. From APUs to RGB, Sunny has a handle on all the latest tech news.
